My wife and I enjoy playing the iPhone game LetterPress which was recently released by atebits. Atebits’s lead developer is Loren Brichter, who also wrote Tweetie, which became the official Twitter app for the iPhone, writes some great software. So, if you have not done so already, you should definitely try this free game [and then make the in-app purchase if you enjoy it]. That being said, I did come up with one tiny complaint.
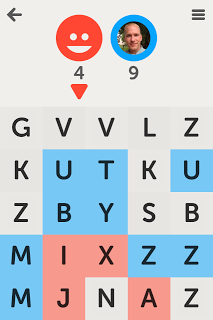
Recently a board came up which five “Z”s, two “V”s, two “K”s, an “X”, and a “J”. Those letters are five of the seven least used letters in the English dictionary, only “Q” and “W” were missing. Almost half of the game board was composed of very infrequently used letters. The game was still playable, but I thought that gameplay might be a little better if concentrations of infrequently used letters were minimized. I think that the chance of getting a “Z” on any given tile should be less than 1 in 26, and instead of just complaining about the game I decided to see what it would take to create an improved random letter generator.
I wanted to know how the letters were distributed in the English language, so I started by creating a small python script which would count the frequency of letters in the English dictionary. I ran the script, which is published on github, against the unix system dictionary (/usr/share/dict/words) and got the following results:
a 196995
c 100944
b 39038
...
y 51542
x 6840
z 8230
Next, I wrote a script which would calculate the probability of each letter and format those results for the final script, which will perform the random letter selection. For the final script I wanted to use a binary tree to make lookups easier, so the output from the second scripts takes this into account. The script assumes that the binary tree will be filled starting with the most frequent letter to the least frequent in a top-down, left-to-right manner. The tree needs to be flattened into a number line so that the number range for each node can be calculated based upon its probability and position in the tree. The leftmost node of the tree will start at zero and the rightmost node in the tree will end with one. In this example the letter ‘E’, which is the most likely, will be 0.105022804 units long, starting at 0.538979491 and ending at 0.644002294 on the number line.

Once the number line ranges for each letter are calculated, the list is sorted by frequency again so that the tree will build properly in the final script. This following data is output form the second script:
('e', 0.105022804, 0.538979491, 0.644002294)
('i', 0.089845073, 0.267441153, 0.357286225)
('a', 0.088258618, 0.785527013, 0.87378563)
('o', 0.07619197, 0.105176925, 0.181368894)
('r', 0.071804464, 0.418384245, 0.490188708)
('n', 0.070815226, 0.682697737, 0.753512962)
('t', 0.067765522, 0.903911257, 0.971676778)
('s', 0.061441654, 0.023092087, 0.08453374)
('l', 0.057969911, 0.198858882, 0.256828792)
('c', 0.045225401, 0.366164283, 0.411389683)
('u', 0.039043109, 0.496249139, 0.535292247)
('p', 0.033992527, 0.647066784, 0.68105931)
('m', 0.030812, 0.754715013, 0.785527012)
('d', 0.030125626, 0.873785631, 0.903911256)
('h', 0.028323223, 0.971676779, 1.000000001)
('y', 0.023092087, 0.0, 0.023092086)
('g', 0.020643184, 0.084533741, 0.105176924)
('b', 0.017489987, 0.181368895, 0.198858881)
('f', 0.01061236, 0.256828793, 0.267441152)
('v', 0.008878057, 0.357286226, 0.366164282)
('k', 0.006994561, 0.411389684, 0.418384244)
('w', 0.00606043, 0.490188709, 0.496249138)
('z', 0.003687243, 0.535292248, 0.53897949)
('x', 0.003064489, 0.644002295, 0.647066783)
('q', 0.001638426, 0.681059311, 0.682697736)
('j', 0.00120205, 0.753512963, 0.754715012)
For simplicity that output is slightly modified and pasted into the third script as the body of the variable ‘letter_list.’ The third script uses this data to build a binary tree with knowledge of each letters range on the number line. A random number between zero and one is generated and the tree is searched to find the corresponding letter.
17:15:10 stollcri>./random_letter.py 25
e c a s i i h b p q t r o u a t r c i e i t a t m
17:15:17 stollcri>./random_letter.py 25
i g o o s u a e o p e i g o e t n l o d a s e f i
17:15:21 stollcri>./random_letter.py 25
c r c c e u o d r m a u e n w e a h o g s e i i r
17:15:25 stollcri>./random_letter.py 25
u s s n m t c n l b l i p t a a c l a i i e s n a
17:15:26 stollcri>./random_letter.py 25
e i o u d x n i s r a l e t a t n i n e n t l o h
17:15:29 stollcri>
We can now select random letters roughly based upon how likely the letter is to appear in the English language. However, now there is over a ten percent chance that the letter ‘E’ will be selected and a less than one percent chance that any of the seven least common letters will be selected. It would probably be a good idea to manually tune the probabilities by compressing the range; this might further enhance gameplay.




